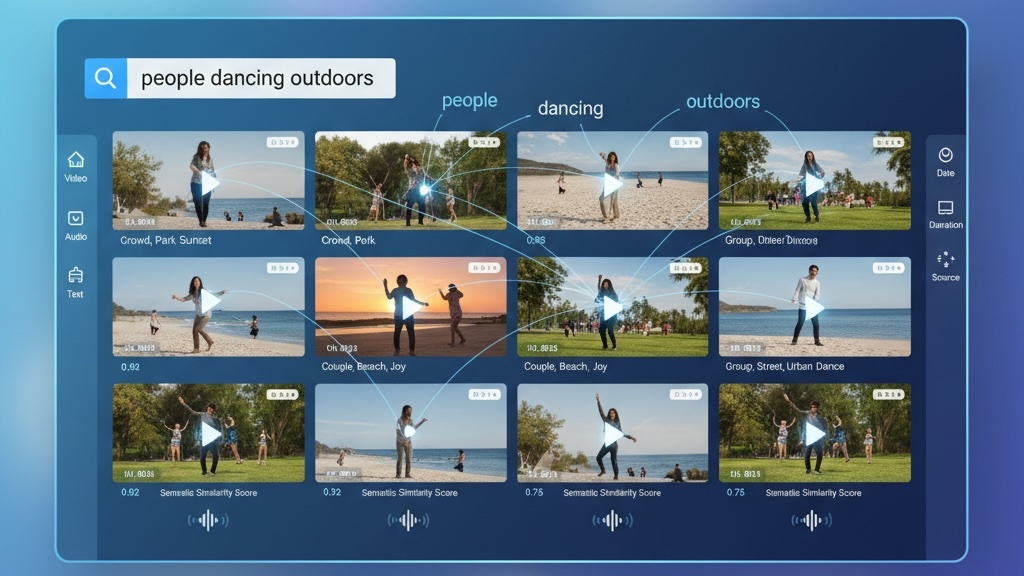
Video Search
Multimodal Embedding Model
A cutting-edge multimodal embedding model designed specifically for video search. Our model understands visual content, audio, speech, and context to deliver accurate semantic search results across your entire video library.